
在《星际争霸2》中,AlphaStar已经进化出了两个版本并都取得了超人的表现
今年1月,人工智能(AI)巨头DeepMind宣布,它在构建类似人类认知的人工智能系统的道路上取得了一个重要里程碑。AlphaStar是DeepMind利用强化学习技术设计的一款代理程序,能够在《星际争霸2》(StarCraft II)中击败两名职业玩家。《星际争霸2》是有史以来最复杂的实时战略游戏之一。在第一个版本之后DeepMind继续进化AlphaStar,现在这名人工智能玩家能够以大师级别进行完整的《星际争霸2》的比赛并宣称超过了99.8%的人类玩家。研究结果最近发表在《自然》杂志上,展示了现代人工智能系统中使用的一些最先进的自我学习技术。
使用强化学习来进行多人游戏并不是什么新鲜事。近几个月来,OpenAI Five和DeepMind的FTW等人工智能机构展示了通过强化学习掌握现代游戏《Dota 2》和《雷神之锤3》。然而《星际争霸2》并不是一款普通的游戏。《星际争霸2》的环境要求玩家平衡高级经济决策和对数百个单位的独立控制。为了精通游戏,AI代理需要解决几个关键挑战:
·探索-开发平衡:在《星际争霸2》中没有单一的制胜策略。在任何时候,AI 代理都需要平衡探索环境的需求,以扩展其战略知识,而不是采取可以立即产生收益的行动。
不完善的信息:不像象棋这样玩家可以观察整个环境的游戏,《星际争霸2》从不呈现任何给定时间的完整环境配置。从这个角度来看,AI代理需要能够使用不完美的信息进行操作。
长期规划:一个典型的《星际争霸2》游戏大约需要 30分钟才能完成,在此期间,玩家不断采取行动来执行整体战略。在游戏早期采取的行动可能要到更晚才会生效,这需要持续的长期规划能力。
实时:一件事是战略规划,另一件事是实时战术规划 在经典国际象棋中,玩家可以安全的花1个小时来评估单个任务,但在《星际争霸2》中行动需要实时进行。从人工智能的角度来看,这意味着代理需要实时评估数千个选项,并检测出最适合长期策略的选项。
超大行动空间:如果你认为 19×19 围棋是一个大的 AI 环境,请再想一想。星际争霸 II 环境要求玩家在任何给定时间控制数百个单位,并且动作的组合组合与环境的复杂性成正比。
为了应对上述挑战,DeepMind最初依靠一种自我学习策略,让AlphaStar的代理通过与自己对战来掌握《星际争霸》游戏。AlphaStar架构的核心是一个深度神经网络,它从游戏界面接收输入数据,并输出一系列动作。神经网络最初是使用传统的监督学习,利用暴雪发布的匿名人类游戏数据集进行训练的。最初的训练让AlphaStar能够以相当高的水平掌握比赛的初始策略,但距离击败职业选手还差得很远。
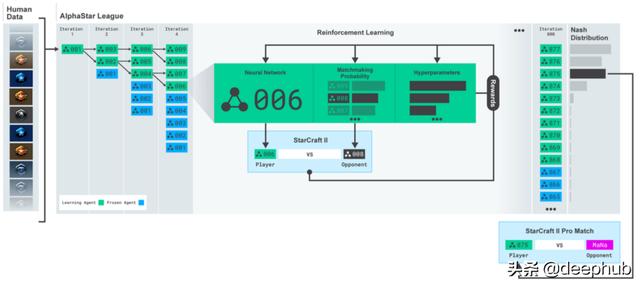

在AlphaStar能够成功玩《星际争霸2》之后,DeepMind团队创造了一个多代理的强化学习环境,在这个环境中,多个代理变体将与自己对战。该系统名为 AlphaStar 联盟,系统允许代理通过与专门用于该策略的特定版本对战来改进特定策略。
尽管 AlphaStar 的早期版本取得了令人瞩目的成就,但 DeepMind 团队发现了一些阻碍代理在职业比赛中取得顶级表现的挑战。一个经典的问题是“遗忘”,尽管 AlphaStar 有所改进,但代理不断忘记如何战胜自己的先前版本。新的 AlphaStar 结合了一系列模仿学习(Imitation Learning)方法,以防止代理忘记学习到的策略。
当 DeepMind 团队意识到 AlphaStar 联盟的原始版本不足以持续提高 AlphaStar 的水平时,提出了一个更艰巨的挑战。想想《星际争霸2》的人类玩家是如何提高自己的技能的,人类玩家会选择一个训练伙伴来帮助他进行特定策略的训练(陪练)。他们的训练伙伴不是为了战胜所有可能的对手而比赛,而是在暴露他们朋友的缺点,帮助他们成为更好、更强大的玩家。这种方法与之前版本的 AlphaStar 联盟形成了鲜明对比,因为在联盟中所有玩家都专注于获胜而不是改善自己的弱点。为了应对这一挑战,新版本的 AlphaStar 创建了一个新版本的联盟,主代理目标是赢得和每个人的比赛,而暴露者代理(exploiter agent)侧重于帮助的主代理发现和修改弱点而不是最大化自己的胜率,通过将这两种策略进行结合一起进行训练。
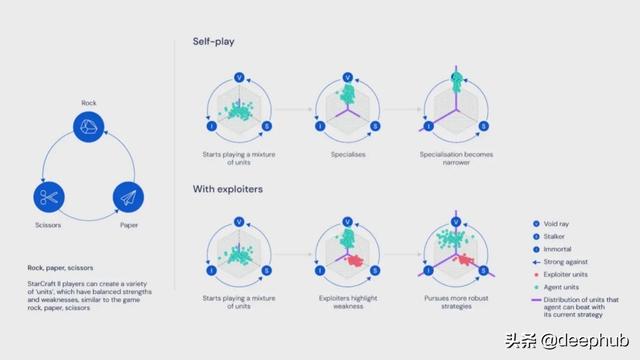
下图可能有助于解释暴露者代理如何帮助创建更好的策略。在游戏中玩家可以创建不同的单位(农民、战士、运输机……),这些单位可以部署在不同的策略动作中,类似于石头剪刀布游戏。由于某些策略更容易改进,因此朴素的强化学习模型将专注于那些策略,而不是其他可能需要更多学习的策略。暴露者的作用是突出主代理的缺陷,迫使他们发现新策略。同时,AlphaStar 使用模仿学习技术来防止代理忘记之前的策略。
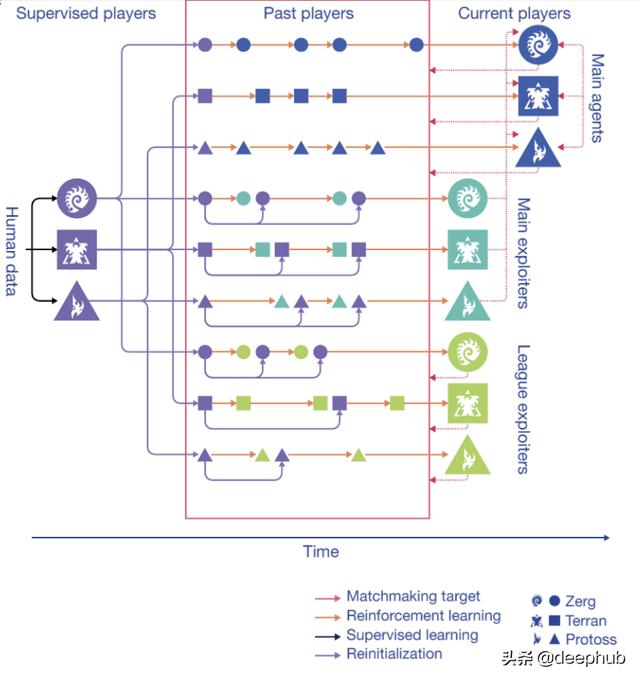
让我们从技术视角看一下新 AlphaStar 训练环境。它包含三个代理池,每个都由监督学习进行初始化,随后用强化学习进行训练。 在训练过程中,这些代理会周期性地将自己的副本——被冻结在特定时间点的“玩家”——添加到联盟中。 主代理与所有这些过去的玩家以及他自己进行训练。暴露者代理针对所有过去的玩家进行训练。 主要暴露者针对主代理人进行训练。 主要暴露者和联盟暴露者在向联盟添加新玩家时可以将其初始化为监督学习的代理。
新AlphaStar是《星际争霸2》中第一个达到宗师级别的AI代理。构建AlphaStar的经验可以应用于许多自学习场景,如自动驾驶汽车、数字助理或机器人,在这些场景中,代理需要在组合行动空间中做出决策。AlphaStar表明,自学习人工智能系统可以应用于现实世界的许多复杂场景,并取得了令人瞩目的效果。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
 微信扫一扫
微信扫一扫