
涉及到几个手段,分别是:
1.14d检验法
1.2Q检验法
1.3Grubbs检验法
1.4偏态-峰态数据分布正态性检验法
1.5相对极差
1.6STD、RSD
说明:本文公式均为Excel公式,那种大计算公式懒得敲。
对于以上6种手段,其中1-3为离群值的剔除,4也可以做离群值的剔除,详见GB/T 4883-2008偏度-峰度检验法,5-6为整体离散度的一个判断。

图片来自百度,侵删。
离散程度,英文名Measures of Dispersion,是指通过随机地观测变量各个取值之间的差异程度,用来衡量风险大小的指标。
定义来自百度百科。
2.1相对极差:
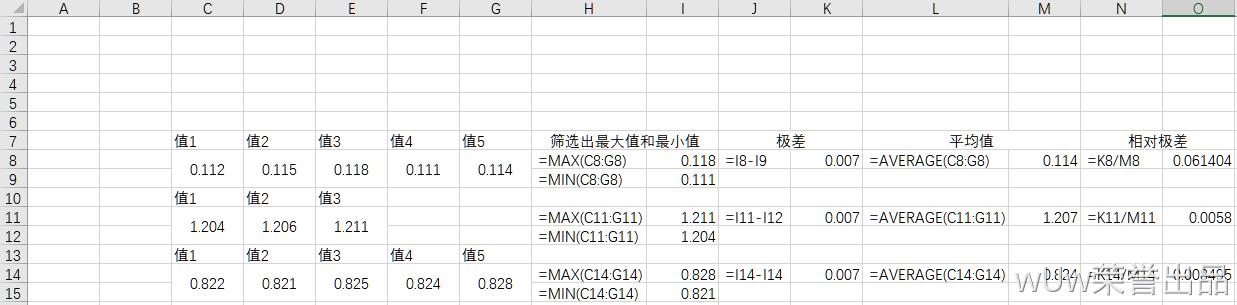
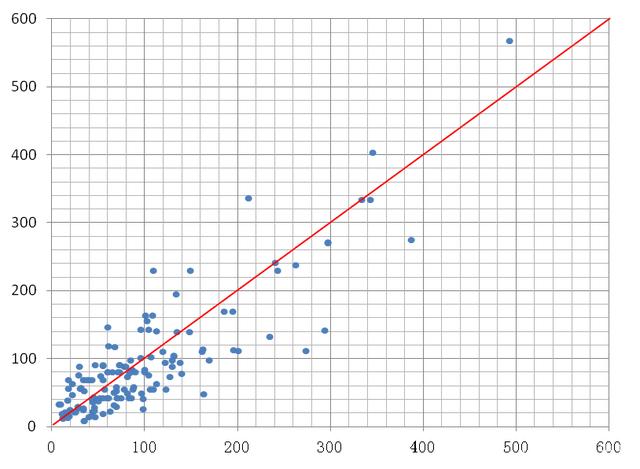
示意图2.1
极差:
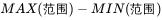
对比上图可以看得出来,极差做的就是离散的判断,最基本的计算,所以也叫做全距。
相对极差:
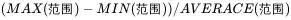
对比上图可以看得出来,引入平均值后,对于相同极差的数据也能够体现出不同的离散度。
但是相对极差不如极差显著。
2.2STD、RSD:

示意图2.2
STD:
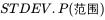
对比示意图2.2可以看出来,两组数据的离散是一致的,但是两组数据实际并不在一个范畴中,一个属于1以下,一个属于10以上。标准偏差是每个值与平均值比较,因为乘方的关系会扩大这种差异,对于1、2、3、4、5和1、2、2、5、5这种数据,极差是无法处理的,标准偏差就可以明确的给出离散程度的区别。
可以看下面这个示例:

示例图2.2
RSD:
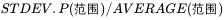
对比示意图2.2可以看得出来,相对标准偏差体现出了两组范畴不同的数据的差别,同样也因为这个平均值,对于10.112和0.112这两组数据就明显体现出精密度的差别了,一个是五位有效数字一个是三位有效数字,同样波动下,显然五位有效数字这组精密度更好。
上面的方法做了离散度的判断,那么具体有哪些值离群了呢?是否可以非主观的去判断离群值从而方便查找原因和数据处理呢?
有。
3.14d检验法:很简单的小方法,问题也不少,先说计算。

示意图3.1
4d检验法
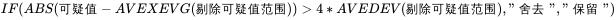
适用于10个数据以上的处理,如果数据量在5~10,可以酌情使用2.5d,问题是数据量不够的时候(<10),容易无法正确判断是否离群值。
3.2Q检验法:适用于10个数据以内的处理。
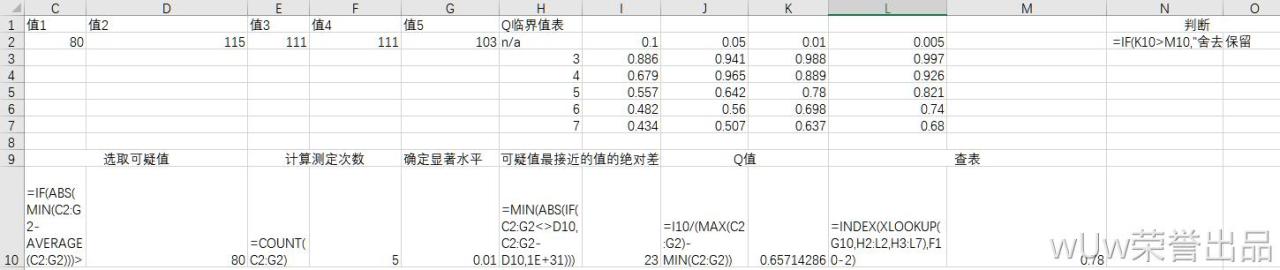
示意图3.2
Q检验法:
3.2.1选取可疑值:
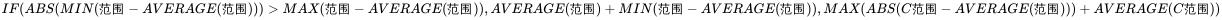
3.2.2计算测定次数
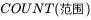
3.2.3与可疑值最接近的值的绝对差值
3.2.4Q值
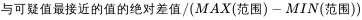
3.2.5查表
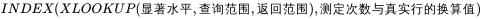
这里解释一下,数据是5个没错,但是因为查询表返回的数值是以0.01那行开始计算的,index的作用是返回对应行、列的数值,那么查出来0.01那一列的数据,如果用5,就会查到7和0.01交叉的数值,但是数据实际是n=3开始的,所以要-2。
3.2.6判断
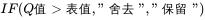
3.3Grubbs检验法:
示意图3.3
Grubbs检验法:
3.3.1上侧
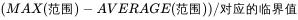
3.3.2下侧
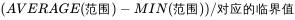
3.3.3判断
IF(上侧临界值,"上侧检出:"&MAX(范围),"上侧未检出")&","&IF(下侧临界值,"下侧检出:"&MIN(范围),"下侧未检出")
稍做一下改变:

示例图3.3.3-1
再做一下改变:
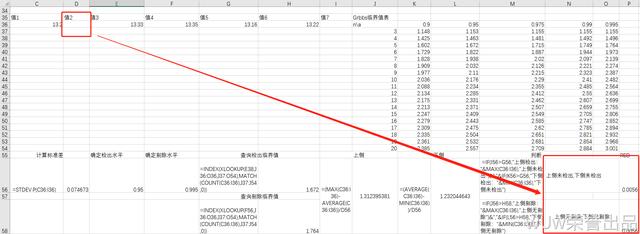
示例图3.3.3-2
还做一下改变:
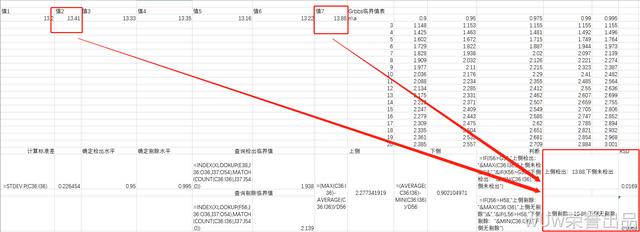
示例图3.3.3-3
对于检测来说,如果整组数据RSD符合就没必要再去剔除离群值。
3.4偏态-峰态数据分布正态性检验法:
数据是正态分布以上手段才是有效的。那么就验证正态分布吧。
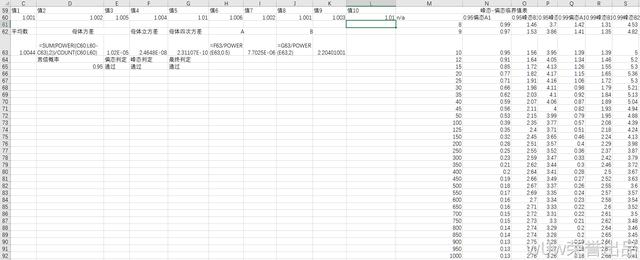
示意图3.4
偏态-峰态数据分布正态性检验法:
3.4.1母体方差
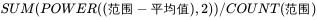
解释一下power函数中的2改3、改4就可以。
3.4.2A偏态
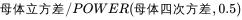
解释一下,0.5即开方。
3.4.3B峰态
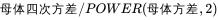
3.4.4判断
偏态判定:IF(偏态<INDEX(XLOOKUP(置信概率&"偏态A1"查询范围,返回范围),MATCH(COUNT(范围),范围,0)),"通过","不通过")
解释一下,match中的0为精确查找,就是=。
峰态判定:IF(AND(INDEX(XLOOKUP(置信概率"峰态B1",查询范围,返回范围),MATCH(COUNT(数据量,范围,0))<峰态,峰态<INDEX(XLOOKUP(置信概率&"峰态B2",查询范围,返回范围),MATCH(COUNT(范围),范围,0))),"通过","不通过")
最终判定:

这东西没有一定数据量没啥意义,一般会结合Grubbs剔除异常值后去做,先上100个数据。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
 微信扫一扫
微信扫一扫