
(1)爬行和抓取:搜索引擎蜘蛛利用追踪链接察觉和网页访问,读取网页页面HTML编码,存进数据表。
(2)数据预处理:数据库索引程序对获取来的网页页面数据实现文字提取、中文分词、索引、倒排索引等处理,以作排名程序流程调用。
(3)排名:用户输入查询词(关键词)后,排名程序流程启用数据库索引数据,计算相关性,随后按一定格式转化成搜索结果页面。
爬行和抓取是搜索引擎工作的第一步,完成数据采集的小任务。搜索引擎用于爬取页面的程序被称之为小蜘蛛(spider)
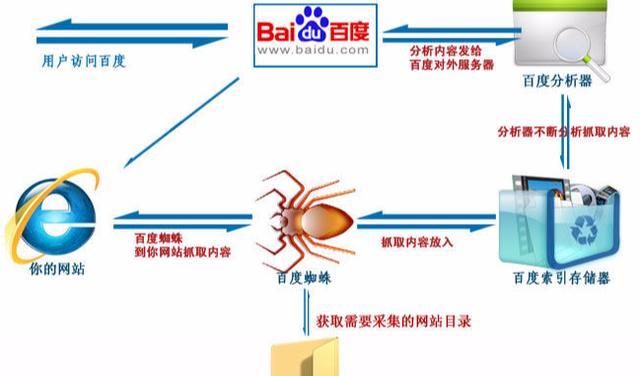

一个合格的SEOer,要想让自身的大量页面被百度收录,就要想法想方设法吸引蜘蛛来爬取。
(1)网站和网页页面的权重,质量高、时间长的网站通常被认为权重比较高,爬行深度也会比较高,被百度收录的网页页面也会越多。
(2)页面的更新频率,蜘蛛每一次爬行都会把网页页面数据储存起來,如果第二次,第三次的抓取和初次的一样,表明没有更新,长此以往,蜘蛛也就没有必要常常爬取你的网页页面啦。如果内容经常性更新,蜘蛛就会频繁页面访问,来爬取新的网页页面。
(3)导入链接,不管是内链还是外链,要想被蜘蛛抓取,就必须有导入链接进入网页页面,否则蜘蛛就不会知晓网页页面的存在。
(4)与首页的点击距离,一般网站上权重最高的是首页,绝大多数外部链接都是指向网站首页,那么蜘蛛访问最频繁的网页页面就是网站首页,离首页点击距离越近,页面权重越高,被爬行的机会越大。

坚持不懈有频率的更新网站內容,最好是高质量的原创内容。
主动向搜索引擎提供我们的新页面,让蜘蛛迅速的发觉,如百度的链接提交、抓取诊断等。
建立外部链接,可以和相关的网站做友情链接交换,可以去别的平台发表高质量的文章指向自己的网页页面,具体内容要相关。
制作网站地图,每个网站都应该有一个sitemap,网站所有的页面都在sitemap中,方便蜘蛛抓取。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
 微信扫一扫
微信扫一扫